






")





")

")
")
 in Excel & Google Sheets")




If you’re trying to find duplicates in new lines inside cells in Google Sheets, the following formula can help:
=LET(txt, ARRAYFORMULA(TRIM(SPLIT(A1, CHAR(10)))), UNIQUE(FILTER(txt, COUNTIF(txt, txt)>1), TRUE))Just replace A1 with the target cell reference.
Example: Find Duplicates in Multiline Cells in Google Sheets
Let’s say you have the following text in cell A1 (each item entered on a new line using Alt+Enter):
Apple
Banana
Orange
Apple
Grapes
Use this formula in cell B1:
=LET(txt, ARRAYFORMULA(TRIM(SPLIT(A1, CHAR(10)))), UNIQUE(FILTER(txt, COUNTIF(txt, txt)>1), TRUE))Result: It will return "Apple" – the duplicate entry in that cell.
What If There Are Multiple Duplicates?
If cell A2 contains:
Apple
Banana
Orange
Apple
Grapes
Grapes
The formula in cell B2 will return "Apple" and "Grapes" across B2 and C2:
=LET(txt, ARRAYFORMULA(TRIM(SPLIT(A2, CHAR(10)))), UNIQUE(FILTER(txt, COUNTIF(txt, txt)>1), TRUE))Formula Explanation
The formula works by breaking the cell content into separate lines and checking for repeated values:
ARRAYFORMULA(TRIM(SPLIT(A1, CHAR(10))))– splits the multiline content by line breaks and trims any spaces.COUNTIF(txt, txt)>1– identifies repeated values.FILTER(...)– filters only those values that occur more than once.UNIQUE(..., TRUE)– ensures each duplicate is listed only once.
This is a handy way to find duplicates in multiline cells in Google Sheets, especially when entries are separated by line breaks within the same cell.
Highlight Cells Containing Duplicates
Google Sheets doesn’t allow you to highlight individual values inside a cell, but you can highlight the entire cell if it contains duplicates.
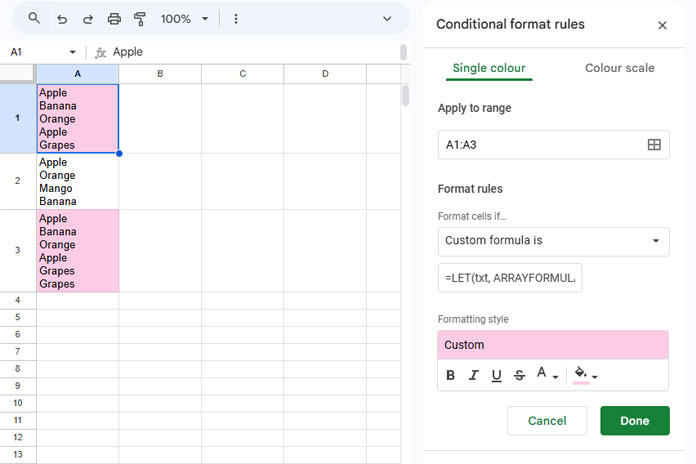
Here’s how:
Use the modified formula to return the count of duplicate values:
=LET(txt, ARRAYFORMULA(TRIM(SPLIT(A1, CHAR(10)))), COUNTA(IFNA(UNIQUE(FILTER(txt, COUNTIF(txt, txt)>1), TRUE))))IFNA(...)suppresses errors when there are no duplicates.COUNTA(...)returns the number of duplicate entries found.
Apply Conditional Formatting
- Select your range (e.g., A1:A).
- Click Format > Conditional Formatting.
- Under Format Rules, choose Custom formula is.
- Enter the above formula.
- Choose your preferred formatting style.
- Click Done.
Now, any cell containing duplicate values in new lines will be highlighted. This approach provides a visual way to find duplicates in new lines inside cells in Google Sheets.